
Информационный дизайн
Пиктограммы для транспортных узлов
Американская ассоциация дизайнеров AIGA публикует на своем сайте набор из 50 пиктограмм, которые могут использоваться для направления людей в транспортных системах и узлах. На вокзалах, аэропортах и т. д. Дизайн пиктограмм уже фактически стал стандартом, получил всяческие признания и рекомендуется к использованию.

Взять это богатство можно тут:
Gliffy - рисование диаграмм он-лайн
Вот этот проект предлагает инструмент для рисования диаграмм прямо в браузере:
Интерфейс довольно удобен, а функционал достаточен для основных задач. Готовые диаграммы можно шарить, печатать, экспортировать в визио, джипег или png.
Есть бесплатная и платная версия.
Опросы коллег и друзей улучшат вашу работу
Как известно, у нас все разбираются в машинах, футболе и веб-дизайне. Заказчик или советчик не применет вставить дизайнеру свое суждение по любому вопросу. Если дизайнер не сможет аргументированно возразить и убедить оппонента в своей правоте, возможно ему придется переделать работу против своей воли.
У людей существует большое количество убеждений на счет конструкции разных вещей на сайте. Дизайнер, предлагающий новое смелое решение непременно с ними столкнется. Ему надо всеми способами убедить людей, привыкших жить в своем монастыре, в том, что его новый устав лучше.
К сожалению, я не знаю гарантированных методик насаждения своего мнения. На работе я всего лишь управляю проектом нашего сайта и дизайню какие-то вещи. К счастью, я могу внедрять интересные решения, если мотивирую их правильность перед руководством.
В этом плане хорошо работают мини-опросы коллег и знакомых по представленным моделям. Конечно, это малюсенькие (10-20 человек) и не серьезные исследования, но минимальная разбивка респондентов по разным сегментам и личностным свойствам уже позволяет уловить тендецию и использовать ее в своих целях.
В нашей компании работает больше двух сотен человек с разным складом ума. Они очень хорошо группируются в отделы исследований (которые каждый день работают с графиками и аналитикой), маркетинга (у которых хорошо развит здравый смысл), айтишники, продажники, дизайнеры, боссы. Еще я обязательно опрашиваю несколько женщин владеющих невоспроизводимой логикой и нескольких известных мне коллег, которые по большинству вопросов имеют отличные от большинства мнения.
Например, недавно я хотел проверить что думают люди когда видят такой график:
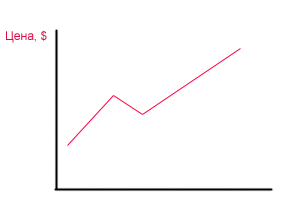
Опрашивались мои коллеги из разных отделов. В целом это примерно соответствует аудитории потребителей подобной аналитики, которую производит наша компания. Каждому респонденту на его рабочем месте демонстрировался график.
Следовал вопрос: "Что находится на этой оси (указывась ось ординат)"
Все опрошенные отвечали "Цена" или "Доллары".
Далее следовал вопрос: "Что находится на этой оси (указывалась не подписанная ось абсцисс)".
80% опрошенных с минимальными раздумьями отвечали "Время".
Конечно, ответ был предсказуем, ведь по словам Эдварда Тафти большинство публикуемых графиков - это динамика чего либо во времени, поэтому люди уже интуитивно готовы к таким данным. Но для меня важно то, что в результате этого опроса я могу лепить на ось абсцисс все, что захочу и буду защищать это от критиков имея в арсенале не только незнакомого им Тафти, но и мнение общественности :)
Подобные опросы можно проводить так же для проверки гипотез. Вот, например, извечная проблема: как визуально изображать результаты нескольких замеров времени, в которых лучшим результатом является минимальный.
Когда я рассматриваю компьютерные тесты, я постоянно путаюсь, потому что вслед за графиком fps-ов может идти график времени обсчета. А у этих графиков лучшие значения стремятся абсолютно в противоположные стороны. Соответственно, я подумал, что для графика затраченного времени надо перевернуть шкалу. Поэтому я нарисовал вот такую картинку и стал показывать коллегам:
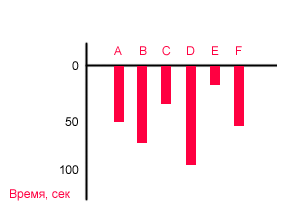
Я демонстрировал график человеку и спрашивал: "Какой результат лучше?"
Потом я спрашивал: "Какой результат хуже?"
И, наконец: "Почему ты так решил?"
Тут все оказалось не так просто.
- Все доступные мне дизайнеры сказали, что лучше результат E, потому что шкала перевернута.
- Маркетологи подозрительно спрашивали "смотря что мерить", но 50% сказало, что E.
- Ресерчеры, которые каждый день работают с графиками, 80% сказали, что E, но либо не знали почему, либо заметили что шкала отрицательная.
- Айтишники подкачали. Только 30% были за E. Правда айтишники у нас все мужского пола, и на вопрос "Почему?" резонно отвечали "Потому что D - больше".
- Женщины 90% сказали что лучший результат - D. Либо потому что он больше, либо пытали "а что сравнивают?".
- Девиантные экземпляры в единичных числах вообще не поняли график.
Отсюда я понял, что такая конструкция имеет право на жизнь, но надо ее модифицировать как-нибудь так:
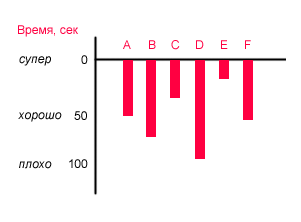
Итого, мини-опросы коллег показали свою полезность. Ими можно аргументировать свое мнение, разбивать чужие убеждения. Ими же можно вправлять собственное вывихнутое самомнение. Скорее всего они будут иметь большую долю ошибочности, но при удаче покажут верное направление в котором стоит двигаться.
Лица Чернова: многофакторный анализ простым наглядным способом
Лица Чернова (Chernoff Faces) - это схема визуального представления многофакторных данных в виде человеческого лица. Каждая часть лица: нос, глаза, рот - представляет собой значение определенной переменной, назначенной для этой части (всего 18).
Основная идея в том, что для человека очень естесственно смотреть на лица, ведь все люди делают это каждый день. Поэтому анализ данных получается эдаким "натуралистичным". Легко делать сравнения и легко выявлять отклонения. Даже блондинки смогут производить многофакторный анализ значительного количества данных.
В 1981 году Бернард Флури и Ганс Ридвил (Bernhard Flury and Hans Riedwyl) улучшили концепцию и добавили лицам Чернова асимметрию. Таким образом количество переменных увеличилось вдвое - до 36.
Итак, каждое лицо - это массив из 18 элементов, каждый из которых принимает значение от 0 до 1. Значению соответствует внешний вид соответствующей части лица. Параметры исследуемых объектов приводятся к этим значениям. Экстремумы реальных данных будут приняты как 0 и 1. Все остальное - лежащим в этом промежутке. По полученному массиву конструируется лицо.
Вот какие параметры задаются у лица:
- Размер глаза
- Размер зрачка
- Позиция зрачка
- Наклон глаза
- Горизонтальная позиция глаза
- Вертикальная позиция глаза
- Изгиб брови
- Плотность брови
- Горизонтальная позиция брови
- Вертикальная позиция брови
- Верхняя граница волос
- Нижняя граница волос
- Обвод лица
- Темнота волос
- Наклон штриховки волос
- Нос
- Размер рта
- Изгиб рта
Сложность заключается в правильном сопоставлении исследуемых переменных с частями лица. При ошибке важные закономерности могут остаться незамеченными.
Флури приводит пример удачного многофакторного анализа с помощью лиц. Он проанализировал 100 реальных и 100 поддельных банкнот по параметрам размера границ, отступов и диагоналей. Вот что получилось:
Поддельные банкноты четко выделились в отдельную группу. Таким образом анализ позволил выявить различающиеся группы объектов.
Асимметрия позволяет рассматривать объекты в прогрессе. Второй пример показывает различные факторы у пациентов, к которым применялось лечение. Левая сторона лица показывает значения параметров до, а правая - после лечения.

Посмотрите как изменилось состояние параметров. Легко можно понять кому и насколько стало лучше, даже не вникая в сущность исследуемых параметров.
Статью Graphical Representation of Multivariate Data by Means of Asymmetrical Faces (by Bernard Flury and Hans Riedwyl) можно почитать на JSTOR
http://www.jstor.org/stable/2287565
Если у вас ее нет, я могу вам ее прислать в обмен на интересую ссылку, о которой я еще не знаю.
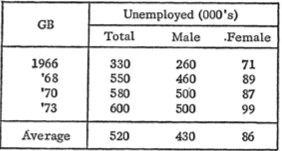
Правила оформления табличных данных. Rudiments of Numeracy by A. S. C. Ehrenberg
A. S. C. Ehrenberg в 1977 году написал и прочитал перед английским Королевским статистическим обществом хорошую и полезную статью о дизайне таблиц: Rudiments of Numeracy. Он привел 6 простых правил как улучшить читаемость, легкость анализа табличных данных и привлекательность таблицы в целом.
1. Округлять к двум значимым цифрам. Не надо приводить в таблицах данные с большой точностью. Для задач сравнения и анализа, человеку вполне достаточно (и будет легче) видеть только две смысловые цифры в каждом числе.
Не так

А так
2. Делать колонку или строку со средними значениями. Это дает дополнительные инструменты анализа самих данных (помогает искать закономерности или распределения. Он даже говорит как это делать. Прицеливаем взгляд на среднее значение, а потом пробегаем по данным).

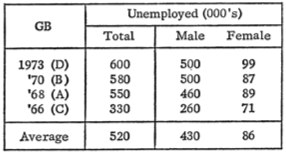
3. Выстраивать числа, предназначенные для сравнения в колонку. Так как глазу гораздо легче пробежаться по колонке, чем по сроке для сравнения данных. Более того, это происходит потому, что сравниваются как правило первые цифры в числе, а остальные пропускаются. Это еще один голос за то, чтобы округлять к двум эффективным числам.
То есть если данные сравниваются, то в плохой таблице для этого надо поменять строки и колонки местами. Вот так:
4. Выстраивать данные в колонках по их величине. Для человека естесственно ожидать более высокого значения наверху столбца. Разумеется, это правило нужно применять если изначально не был задуман другой порядок и он никак не может быть изменен.
5. Оптимизировать раскладку данных. Положение данных в таблице не должно насиловать глаз, пытающийся перепрыгнуть с одного числа на другое.
Вот это ужас
6. Использовать графики с умом. Графики позволяют четко показать качественные характеристики данных, например, зависимости или распределения. Но они плохо показывают количественные характеристики. Иногда график - это просто так хитро разложенная таблица, из за обилия меток на них, просто потому по другому они не могут справиться с задачей.
(Тут, кстати, у автора просто сама форма графика хреновая)
Статья полностью доступна в JSTOR. Доступ туда есть из разных научных заведений типа университетов и библиотек,
ну или я могу прислать ее вам, если напишете и дадите в обмен полезную ссылку.
http://www.jstor.org/pss/2344922
Edward Tufte. Visual Display of Quantitative Information
Прочитал первую книгу Эдварда Тафти Visual Display of Quantitative Information. В ней он описывает все, что касается построения графиков. Как нельзя делать и к чему надо стремиться, чтобы максимально точно, понятно и красиво отображать данные на графиках.
Вот краткое резюме:
- Graphical Excellence: Тафти приводит примеры классных графиков. Графическое качество - это представлении интересных правдивых данных в хорошем дизайне. Оно состоит из комплексных идей четкой, точной и эффективной коммуникации.
- Graphical Integrity: Тут автор приводит пример плохих графиков и говорит как можно врать с их помощью, замусоривать лишним оформлением, запутывать в измерениях и выдирать данные из контекста. Графическая целостность - это недопущение всего этого.
- Sources of Graphical Integrity and Sophistication: Тафти описывает источники проблем плохих графиков: например, многие художники математически неподкованы, статистика вообще считается скучной, а читатели графиков - слишком тупыми для их восприятия
- Data Ink and Graphical Redesign: В этой главе расписана концепция data-ink ("чернила" потраченные на отображение данных). Показано как повысить информативность графиков путем убирания "чернил", не относящихся к делу. Прежде всего нужно показывать данные, максимизировать data-ink, стирать non-data-ink, стирать лишние ненужные "чернила данных" и постоянно проводить ревизии.
- Chartjunk: Vibrations, Grids and Ducks: Тафти разоблачает современных дизайнеров злоупотребляющих лишними заливками и градиентами для создания графиков. Говорит, что разметочные сетки либо вообще не нужны, либо должны быть приглушены. А больше всего он ненавидит "Уток" - вещи, которые существуют только ради дизайна (по примеру дома-утки, который есть архитектурная декорация сама по себе).
- Multifunctioning Graphical Elements: В этой главе приведены отличные примеры графических элементов, которые несут сразу несколько смысловых нагрузок и представляют несколько "слоев" данных.
- Data Density and Small Multiples: Здесь рассматриваются способы увеличения плотности данных на области графика. Про это я писал в прошлом посте
- Aesthetics and Technique in Data Graphical Design: Тафти немного говорит о том, как лучше располагать графики в потоке текста, какого они должны быть размера и как вообще выглядеть. В заключении, он добавляет, что дизайн - это всегда выбор и придется жертвовать чем-то одним в угоду другого. И лучше пожертвовать одним принципом, чем налепить кучу бессмыссленных точек на бумаге.
Саму книгу можно найти на torrents.ru и если не стерли, что еще и здесь
http://avolon.livejournal.com/22911.html
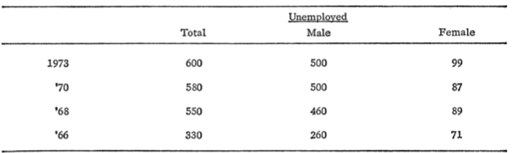
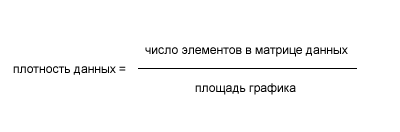
Индекс плотности данных на графике
Тафти приводит индекс "плотности данных" на графике. Вот такой.
Для примера возьмем вот этот график.
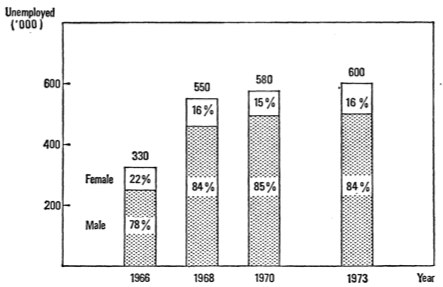
На нем изображено всего 5 цифр. Посчитаем площадь области данных в сотнях пикселей в квадрате, применим формулу и получим плотность данных 0.04 - что не фонтан.
Вот в таком графике отмечено уже 8 цифр на примерно такой же площади. По расчетам получается плотность 0.08
В заключение вот таблица из Тафти о числе цифр на квадратный дюйм в различных изданиях.
|
datadensity.pdf (размер 266.29 КБ) |
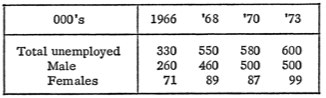
Выбор величин в таблицах помогает правильно сравнивать данные
У нас в компании было обсуждение с консультантом таблиц, которые публикуются в нашем отчете. Вот такое замечание выдал консультант:

Сравнивать данные в таблицах должно помогать не только оформление, но и величины этих данных. В этой таблице величины визуально равны, и получается, что во всем Краснодаре меньше гипотетических квадратных метров, чем на одного человека. Надо переделать хотя бы так:

Теперь зритель быстро понимает, что второе число намного больше первого. Идеально, конечно, использовать одинаковые величины.
Убирание лишней шкалы на графике
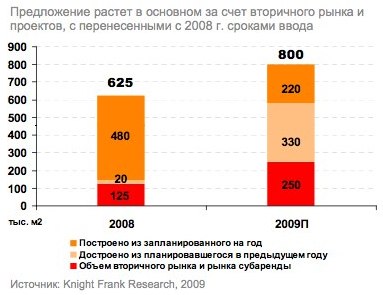
Всем известен вот такой график из двух параметров
Тафти говорит, что незачем на шкале рисовать лишние линии. Это только увеличивает количество чернил, потраченных впустую. Надо делать так.
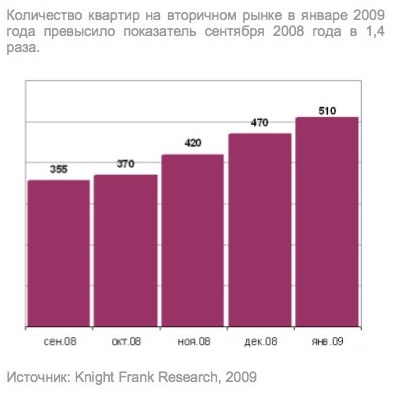
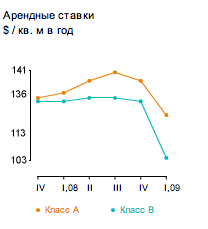
Попробуем на практике. Вот наш график с сайта Knight Frank
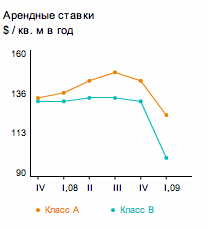
Получается. На оси Y автоматом видны минимальные и максимальные значения (вообще этот график, конечно, еще можно улучшить).
Кампания Наполеона в России 1812 года. Классический график
Вот классическая работа французского инженера Чарльза Джозефа Минара (Charles Joseph Minard) 1781-1870 о походе Наполеона в Россию.
Маленький график рассказывает огромное количество исторической информации. Толстые линии - это численность французской армии до наступления и после. Обратите внимание на привязку к географической информации. Во время отступления так же идет привязка к температуре.

Полная версия:
|
napoleon.pdf (размер 1632.01 КБ) |
График движения поездов - классический пример
Продолжаю читать Тафти. Начал с его первой книжки про графики. Разбирать его примеры - одно удовольствие (выложу ее резюме когда дочитаю).
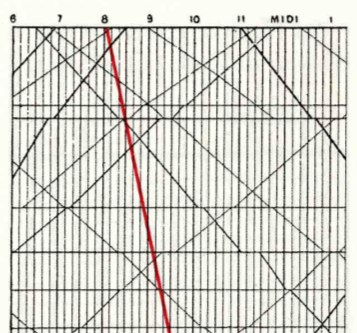
Вот фрагмент графика поездов из Парижа в Лион, созданный в 1880 году. Авторство метода приписывают некоему французскому инженеру Ibry

В верхней строке - часы суток. Станции расположены слева, причем вертикальное расстояние между отметками пропорционально реальному расстоянию между этими пунктами. Диагональные линии представляют движение поездов. Не трудно догадаться, что если диагональ наклонена влево, то поезд следует из Парижа, и наоборот.
Там, где линии пересекаются, поезда втречаются друг с другом. Можно так же отслеживать время остановок.
Чем круче линия, тем быстрее идет поезд. Особенные поезда можно отмечать другим цветом. Вот, скажем, экспресс:
Visual Function by Paul Mijksenaar
Прочитал неплохую книжку
Paul Mijksenaar
Visual Function.
An Introduction to Informational Design
Ее можно взять на Гугле:
http://books.google.com/books?printsec=frontcover&id=-j7JcB2al7sC

Вот про что там написано:
- Form or function: Львиная доля страниц уделена размышлениям, а вернее утверждению и доказательству того, что функция предмета определяет его форму. Главное в предмете то, зачем он сделан, а эстетическая красота идет бонусом. Скажем, быстроходные парусники клиперы считаются одним из самых красивых творений человека, хотя они строились для того, чтобы быстро смыться с грузом контрабандного опиума от правительственных кораблей. Или же роскошные номера на океанских атлантических лайнерах должны были отвлекать пассажиров от блевотной морской болезни. Мийксенар разработал шкалу оценки предмета по трем составляющим, которую я приводил пару постов назад.
- Visual information: Информация будучи представлена в графической форме может сказать о многом, практически без слов. Лев в разрезе гораздо информативней пяти страниц текстового описания своей анатомии. Временной график убыли наполеоновской армии с нанесенными географическими ориентирами очень наглядно показывает где и когда он терял своих людей. Там же приводится в пример визуальный язык Isotype, про который я написал вчера.
- Graphical variables: Жак Бертин (Jacques Bertin) разработал систему визуальных переменных. Такие понятия как цвет, форма, размер и др. были разложены им по полочкам и каждой определены свои функции: иерархии, различия или объединения. Наибольшее признание его система получила в картографии. Там важно отделить один объект от другого. Как это сделать? Выбрать соответствующие переменные. Мийксенар попробовал показать как можно применять эту теорию в других сферах графического дизайна. Я скоро напишу подробнее про его метод.
- Three cheers for the everyday: Мийксенар советует современным дизайнерам больше смотреть по сторонам, подмечать интересные решения в самых обычных вещах и черпать из них вдохновение. Он жалуется что современные дизайнеры считают такой метод пошлостью, а себя - пупом земли.
- Experiment or craftmanship: Он так же говорит, что хороший дизайнер должен постоянно исследовать самые разные вещи и явления. Если человек что-то дизайнит, он должен разбираться в предмете дизайнируемого.
- Trends: Несомненно развитие технологий дошло до такой степени, что теперь нужно не разрабатывать вещь, а потом придумывать ее описание, а сначала описывать, а потом делать.
- Form follows content: Автор еще раз повторяет, что было бы чем наполнить - наилучшая форма сама для этого подберется.
- Regarding training and designers: Мийксенар считает, что с дизайнером неразрывно должен работать человек, максимально понимающий цель разрабатываемой вещи, например заказчик. Он обязан пресекать попытки художественной самореализации в ущерб смыслу.
Наглядные формы представления информации: любопытная система Isotype
В 1930х годах профессор Отто Нойрат (Otto Neurath) возглавлял команду талантливых специалистов, разработавших систему наглядной формы представления информации - Isotype. Они создали так называемый международный изобразительный язык, использующий самоочевидные символы, основанные на научном смысле и психологических экспериментах.
Isotype является прародителем всех современных пиктограмм, но благодаря научно-практическому подходу к своему созданию, обладает свойствами простоты и однозначности дизайна.
Вот книжка на "простом английском", которую написал сам Нойрат, рассказывающая про идею и основы языка.
|
Internationa_Picture_Language._Otto_Neurath.pdf (размер 7829.64 КБ) |
Вот на этом сайте можно посмотреть сканы книжек с примерами использования. Нажмите там на кнопку Back, чтобы перейти к списку дополнительных ресурсов по Изотайпу.
http://www.fulltable.com/iso/menu.htm
А вот пара примеров оттуда (чтобы далеко не ходить).
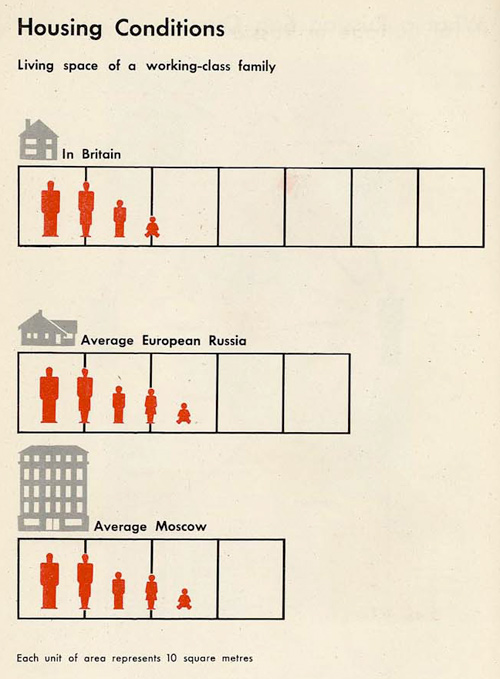

В целом, можно легко использовать этот язык сегодня. Механизм восприятия информации человеком не особо-то и поменялся. Все современные наглядные формы представления информации так или иначе являются развитием идей, описанных в Isotype.


The First Six Books Of The Elements Of Euclid by Oliver Byrne
Пару дней назад я писал о книге XIX века, подающей теоремы Евклида в необычном виде. Я покопался в интернетах, нашел отсканированные страницы этой книги и сделал из них PDF. Можно скачать.
|
euclid_byrne.pdf (размер 84408.33 КБ) |

Цветовое кодирование доказательств теорем Евклида
Тафти продолжает жечь. В главе про цвет отличный пример его использования.
У всех в школе ведь была геометрия? Вспомните, как выглядели все теоремы в учебнике? Примерно вот так:

В 1847 году Оливер Бирн, школьный учитель математики, гм... раскрасил шесть классических книг Евклида о геометрии. Вышло так:

1+1 = 3
Тафти довольно подробно описывает принцип 1+1=3
Его смысл в том, что городя кучу визуальных предметов на изображении, мы производим дополнительные предметы, образующиеся на пространстве между ними.
Это можно использовать во благо, хитроумно зафуфыривая композицию на странице. Вы видите белые объекты?
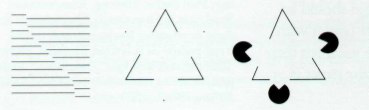

А можно наворотить кромешный ужас.

Дизайн маленького словарика
Вот примеры из двух учебников норвежского языка. В первом примере норвежские слова и их перевод невозможно спутать, так как они различаются жирностью и достаточно отделены пространством друг от друга, а пояснения к слову даются в скобках после перевода. Таким образом, читается слово, сразу же его перевод, а вслед за ним - пояснения. С другой стороны, такой словарь сложно заучить, так как нельзя закрыть перевод, не перекрыв часть норвежских слов.

Во втором примере сразу за норвежским словом даются пояснения, что заставляет глаз прыгать в поиске перевода. Кроме того перевод сильно удален от оригинала, что не добавляет радости предыдущему процессу. Однако тут дано чуть больше информации, так как в пояснении приводятся окончания словоформ, и учить немного легче, потому что можно закрыть перевод рукой или листом.

В первом случае, кстати, словарик занимает гораздо меньше площади. Идеальным был бы первый вариант с возможностью полностью закрыть перевод.
Диаграмма стебля и листьев
В той же книжке Envisioning Information очень понравился пример диаграммы "стебля и листьев" (stem-and-leaf plot). Чистая статистика сама создает дизайн информации. В примере ниже - распределение высоты 218 вулканов. Стеблем является тысячи футов, а листьями - сотни тысяч (каждая цифра представляет сотню тысяч футов высоты одного конкретного вулкана). В результате, рассматривая данные на макро-уровне, мы получаем возможность мгновенно узнать какой высоты вулканов больше, а на микро-уровне - узнать высоту всех вулканов.

Еще понятней пример с расписанием поездов. Стебель - час отправления, а листья - минуты. На малюсенькой площади можно понять когда едет первый и последний поезд, время конкретного поезда, отследить пиковые часы загрузки линий.

Читаю Edward R. Tufte, Envisioning Information
Хорошая книжка по информационному дизайну. Куча примеров. Вот, например, прогноз погоды в Японии.
.jpg)
Серые контуры показывают температуру 0° и 10°, а облачность очень наглядно показана на профиле страны (заодно отлично видно характер местности). Конечно, такой прием работает в основном только для плоских стран, но он очень красив.
Сама книжка на английском языке есть на торрентах.